

It’s complicated. In the beginning videos were easy to make for Spacemesh because my setup was new, and I often redid everything as I learned new things, that all led up to the Ultimate Smeshers Guide. That is now sorely outdated and I need to make another. But I’m not starting from scratch anymore. And my setup has gotten fairly complex. It makes doing videos a bit harder. So to break the ice of 1:N videos I’m going to go over my setup, as well as a bit about 1:N as sort of a precursor to the full Ultimate 1:N guide which I promise I am working on.
Let’s start with a basic server with some HDDs might look like:
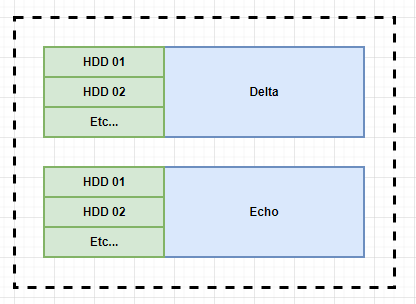
Pretty simple right? Just a server name Delta, with some HDDs and a server named Echo with some HDDs. Let’s assume those HDDs are already filled with PoST Data, and let’s assume there are 10 of them connected to Delta and Echo. Before 1:N you would need a dedicated full node per HDD. It looked like this:
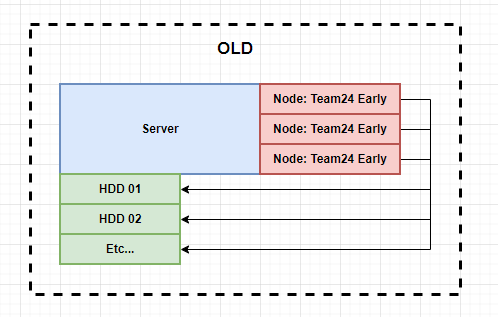
In this example, the server has a node running on the Team24 early PoETs for each set of PoST data. With 1:N, you only need 1 node for all your PoST data as long as it is running on the same PoET. So now it looks like this:
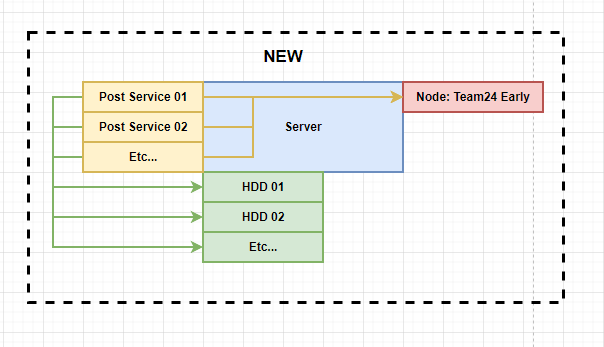
Notice that there is only one node, but now we have a “Post Service” for each set of PoST data. The Post Service is a lightweight service that manages the connection between your Node and your PoST data. As part of this conversion from 1:1 to 1:N you must run Post Services, and then your Node must be converted to run in unsupervised mode, meaning it has no PoST data directly connected to it.
There are a lot of benefits of doing this. The biggest one for me is that outside of the cycle gap, I do not need to have my hard drives powered on. To fully benefit from this I have all of my hard drives in a disk shelf that can be shut off independently of the servers.
My actual current setup looks like this:
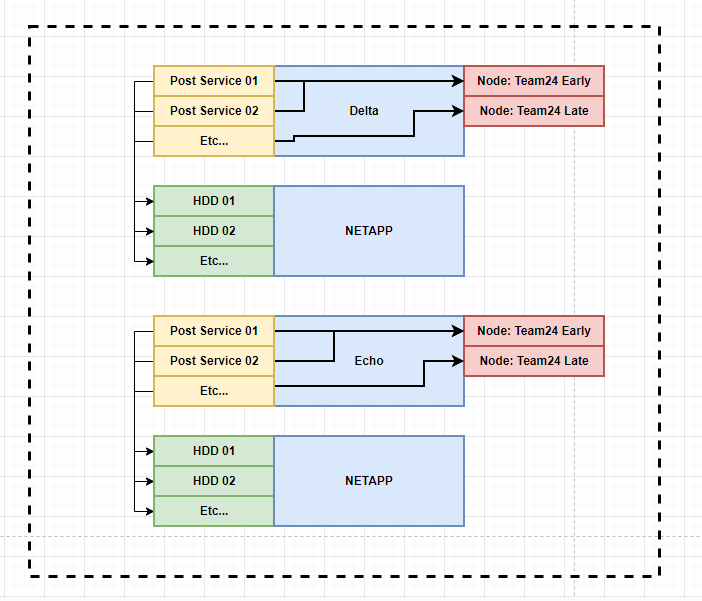
Because you need to run a node for each PoET cycle you will be running on, I have a node for both the Team24 Early and Team24 Late cycle. Then for every HDD in my diskshelf with PoST data, I have a Post Service connected to it. Outside of the cycle gap, when I’m not proving, I shut off the Post Services and diskshelf. Then a few hours before Cycle gap I turn them all back on. This does take a bit of coordination, but it’s worth it to save power and wear and tear. Basically once a week I need to turn on, then turn off my disk shelf. That’s something I can live with.
I have both nodes, and all my Post Services running in docker. It makes it super clean and simple. Some will say it’s overkill, I say it’s neat. It’s really up to you how you want to do it.
Some notes on the 1:N nodes (really 2:N in my case).
Your config must remove all references to smeshing except the coinbase and proving opts if you have them.
Because you only have 1 config per node, you can only use 1 coinbase for all your nodes
Just like only being able to use 1 coinbase, you can also only use 1 set of PoETs per node, so if you need to use 2 or more PoET groups, then you need to run a node for each.
The node is just a node with 1:N. There should be no PoST data directly connected to it. And smeshing needs to be false.
Some notes on the Post Service:
You must run 1 Post Service per set of PoST data
There is no config for the Post Service, it’s all command line arguments
It has it’s own endpoint you can use to query for information
The log output will give you specific information on your proving progress
And that’s really it. In the video I go over exactly what my servers look like and how it’s set up, so make sure to watch the video if you want a bit more information.
Thanks Alex. Very helpful! I’m getting the equipment this week so will set it up and do some benchmarking and come up with a plan. May not be able to use all the disks or space. Will see. Thanks again.
Watched your 1:N videos and read the articles. Had three nodes running and tried to merge those three into two nodes (early and late). Never used team24 so set that up and now have two nodes with two post servers running to early and one running to late. Post data is on SSD. Two are 2TB and last 1TB. Problem is I don’t know if everything is working correctly again. Grafana shows the late node not activating in time (red) and not sure if that is normal. Early node is green. team24 so far only shows one post of 2 early nodes as seen as far as I understand the page. I’ve checked and rechecked configuration and everything seems correct. So I may have to wait until end of this epoch and start of next to see if I’m smeshing again. Your articles and videos are very instructive! Thanks
Thanks Alex. I think I’ve tried this but couldn’t create second container because it could not find spacenet or simple-xxx_spacenet (not home don’t remember entire name), saying it was either not external or couldn’t find it. Anyway I’ll read over this and look at the link and try again once I get home. Thanks. Rand